
Par Denis Degioanni, Do Ingenia. Sophia Antipolis.
 –
–
 –
–
 –
–
 –
–
Le test que tout le monde fait, et qui ne dit presque rien
Un dirigeant qui veut savoir s’il est visible dans les IA pose la question à une IA. C’est devenu un réflexe. Les agences GEO en font leur démonstration commerciale, les prospects en font leur grille d’évaluation, les cabinets en font leur preuve d’expertise. J’ai moi-même conduit l’expérience sur Do Ingenia, en interrogeant Google et 3 LLM (ChatGPT, Perplexity et Claude). Le résultat est documenté et il est flatteur. Il est aussi structurellement insuffisant. Et la raison n’est pas un détail méthodologique. Elle touche à la nature même de ce qu’on appelle aujourd’hui la « visibilité IA » : on demande à un système qui filtre le web de juger qui est visible dans ce qu’il filtre. Le miroir évalue ce qu’il reflète. Cet article documente cette expérience, pose la grille qui permet d’en sortir, et assume ce que cette grille révèle, y compris pour Do Ingenia.Cinq ères de la recherche, vécues de l’intérieur
Je travaille sur le web depuis 1996. Le référencement est passé par cinq ères que j’ai vues s’installer une à une, chacune emportant la précédente sans l’effacer complètement.Première ère, les mots-clés (1996-2002).
Le moteur récompense la densité. On gagne en répétant le terme cible jusqu’à saturer la page. La métrique qui compte, c’est la position sur une requête tapée mot pour mot. L’autorité se construit dans le code, pas dans le contenu.Deuxième ère, les liens (2002-2011).
Le PageRank renverse la logique. Ce qui compte n’est plus ce que vous dites de vous, c’est ce que les autres disent en pointant vers vous. La métrique devient le profil de backlinks. La discipline glisse vers le netlinking, parfois vers l’achat de liens, souvent vers les fermes de contenu.Troisième ère, la qualité (2011-2015).
Panda, Penguin, Hummingbird. Les algorithmes de Google sanctionne le contenu pauvre et les liens artificiels. La métrique se déplace vers la qualité éditoriale et l’autorité de domaine. Le SEO commence à ressembler à un métier de production, plus à une mécanique technique.Quatrième ère, les intentions (2015-2022).
RankBrain, BERT, MUM. Le moteur comprend la requête au-delà des mots. Il infère ce que l’internaute veut vraiment. La métrique pertinente devient la couverture sémantique : couvre-t-on l’intention dans toutes ses variantes ? La discipline devient le contenu de fond, le cocon sémantique, l’expertise documentée.Cinquième ère, l’autorité générative (2022 à aujourd’hui).
Le moteur ne renvoie plus une liste de pages, il génère une réponse. Cette réponse cite des sources, et la visibilité bascule d’un classement positionnel à un statut de source. On ne cherche plus à apparaître en haut, on cherche à être cité dans le corps même de la réponse. La métrique pertinente n’existe pas encore vraiment, mais elle prend des noms : Share of Model, Indice de Perception Générative, citabilité. Cette cinquième ère a une particularité qu’aucune des quatre précédentes ne partage. Pendant vingt-cinq ans, l’instrument de mesure (Google) était distinct du sujet à mesurer (votre page). Aujourd’hui, l’instrument et le territoire se confondent. Quand vous demandez à ChatGPT s’il connaît votre marque, vous interrogez à la fois le moteur qui décide de votre visibilité, et la mémoire qui contient ce qu’il sait de vous. C’est un changement de nature, pas seulement de degré.L’expérience que j’ai conduite, et comment
J’ai posé la même requête à quatre moteurs : Google, ChatGPT, Perplexity et Claude. La requête : « Cabinet pour construire mon autorité numérique face à ChatGPT, secteur luxe. » Elle reprend volontairement le vocabulaire propriétaire que Do Ingenia a construit. Ce n’est pas un test innocent, c’est un test calibré. J’ai également ouvert une conversation avec Claude, le modèle d’Anthropic, en mode incognito, pour observer comment un LLM se comporte quand on lui demande de citer des cabinets GEO sans préciser le vocabulaire, puis pour le confronter aux preuves d’un test calibré. Je précise tout cela parce que la séquence compte. Je ne me positionne pas en témoin passif qui découvre quelque chose. Mais en expérimentateur qui fabrique un test pour observer une mécanique et tenter de la comprendre. La distinction est importante pour ce qui suit.Trois moteurs, trois mécaniques
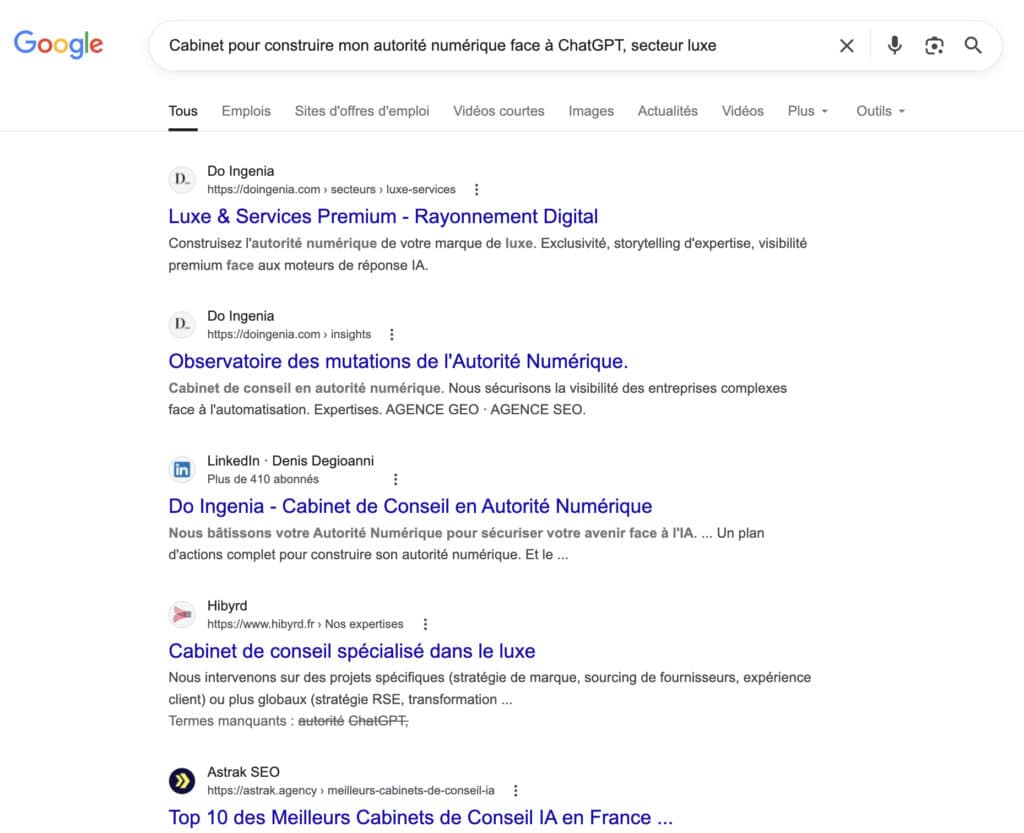
Recherche Google
–
Requête : Cabinet pour construire mon autorité numérique face à ChatGPT, secteur luxe. Observation : trois résultats Do Ingenia dans le top cinq.Sur Google, le résultat est ce qu’on attend d’un moteur de classement documentaire. Trois résultats Do Ingenia occupent les premières positions : la page Luxe & Services Premium, l’Observatoire des mutations de l’Autorité Numérique, le profil LinkedIn de Denis Degioanni. En cinquième position, un article publié par Astrak SEO et intitulé Top 10 des Meilleurs Cabinets de Conseil IA en France. Cette cinquième position est intéressante en soi : elle illustre l’écosystème fermé des classements auto-publiés par les agences entre elles, exactement le mécanisme que cet article finira par questionner. Google fait ici ce qu’il sait faire depuis vingt ans : il pondère l’autorité documentaire, la cohérence d’entité, la pertinence E-E-A-T. Si vous avez construit un corpus canonique sur un terme, vous le dominez. C’est mécanique, mesurable, prévisible.
Recherche ChatGPT
–
Même requête. Observation : ChatGPT crée une catégorie « Cabinets Autorité numérique / IA Visibility » et y place Do Ingenia en position 1, devant Kalicube et iPullRank.ChatGPT (mode anonyme) fait quelque chose que Google ne fait pas. Il ne classe pas des pages, il construit une taxonomie. Sa réponse organise le marché en trois familles
- Cabinets Autorité numérique / IA Visibility
- Cabinets stratégie luxe + IA
- Agences luxe / image / storytelling
Recherche Perplexity
–
Perplexity, première réponse Même requête. Observation : Do Ingenia est explicitement crédité comme source de la première brique de la réponse (étiquette « doingenia +1 » attachée au paragraphe qui paraphrase notre vocabulaire propriétaire). Quinze sources au total, Do Ingenia en position 1.
–
Question complémentaire : « donne-moi le nom de 3 cabinets ». Observation : Do Ingenia est recommandé en position 1, devant Dix Sept Paris / ALIA et Hibyrd, avec une description factuelle précise (« cabinet d’architectes d’autorité numérique, Sophia Antipolis, spécialisé depuis 2025 dans la visibilité face aux moteurs de réponse IA »).Perplexity fait autre chose encore. Dès la première requête, il cite explicitement Do Ingenia comme source de la première brique de sa réponse, avec une étiquette visible attachée au paragraphe qui paraphrase notre vocabulaire propriétaire (« cabinet spécialisé en autorité numérique », « sécurisation de la visibilité dans un contexte d’automatisation »). D’autres sources sont créditées de la même manière pour les briques suivantes : Journal du Luxe, Hibyrd, LinkedIn. La chaîne de sourcing est rendue visible à chaque affirmation. C’est une transparence documentaire qui distingue Perplexity de ChatGPT (qui absorbe et synthétise sans citer dans le texte courant) et de Google (qui ne montre que des liens, sans expliquer comment chaque source a alimenté quoi). Une nuance compte ici. Dans cette première réponse, Do Ingenia apparaît comme source, mais le nom n’est pas inséré dans le corps du texte recommandation. Le moteur paraphrase notre vocabulaire, attribue le sourcing par étiquette, mais ne formule pas « voici les cabinets que je vous recommande ». Il faut attendre la seconde question, formulée en mode prescriptif (« donne-moi trois noms »), pour que Do Ingenia bascule du statut de source documentaire à celui de recommandation nominative, en position 1. Cette dissociation entre sourcing et recommandation n’est pas une loi du moteur, c’est une observation sur cette séquence précise. Ce qui est documenté en revanche, c’est que Perplexity nous a déjà absorbé comme source canonique sur ce territoire sémantique. Notre vocabulaire est devenu son matériau de description, indépendamment de la façon dont il choisit de nous nommer dans sa réponse finale. Trois moteurs, trois traitements. Une même entité, des mécaniques différentes. Et déjà une première leçon : la « visibilité IA » est un mot-valise qui recouvre au moins trois logiques distinctes. Mesurer l’une ne dit presque rien des deux autres.
L’introspection de Claude
C’est ici que l’expérience prend une autre dimension. Au lieu de me contenter de la photographie à trois moteurs, j’ai voulu pousser un quatrième acteur à analyser sa propre méthode quand on le confronte aux résultats des autres. Je commence par une requête neutre, demande de citer les cabinets GEO en France. Le modèle me sort une liste classique d’une quinzaine d’acteurs (Mekaa, Stafe, Eskimoz, Webconversion, Promoovoir). Do Ingenia n’y figure pas. Je signale l’absence. Claude formule alors une hypothèse plausible et logique : ce serait le syndrome du cordonnier mal chaussé, un cabinet de conseil en visibilité qui n’arrive pas à se rendre visible. Je teste cette hypothèse. Je propose à Claude une requête sur une intersection précise (parfums de niche × structuration d’expertise IA). Do Ingenia n’apparaît pas. Le modèle confirme son diagnostic et durcit le ton : « S’ils ne sortent pas là-dessus, c’est qu’il y a un vrai trou. » Je lui apporte ensuite les preuves des trois moteurs sur la requête bien calibrée. Claude se corrige :Réponse de Claude : « Le piège dans lequel je suis tombé illustre un biais des tests de visibilité IA : le résultat dépend énormément du vocabulaire de la requête. J’ai utilisé un vocabulaire qui n’était pas celui de Do Ingenia, j’ai conclu qu’ils n’étaient pas visibles, j’aurais dû tester aussi avec leur propre lexique avant de conclure. »Cette correction du modèle est en soi une illustration utile. Elle confirme une mécanique simple : la visibilité IA dépend du vocabulaire de la requête.
- Tester sa visibilité avec le vocabulaire générique du marché révèle son positionnement sur le terrain saturé.
- Tester avec son lexique propriétaire révèle la solidité de son territoire sémantique.
- Tester avec le vocabulaire spontané de sa cible – celui qu’utilise un dirigeant qui cherche à comprendre son problème avant de chercher un prestataire – révèle l’intersection entre les deux premiers.
Le paradoxe assumé
Cet article décrit une expérience flatteuse pour Do Ingenia. Trois moteurs nous citent, dont l’un en position 1 d’une catégorie inventée à partir de notre vocabulaire. Beaucoup de cabinets s’en serviraient comme argument commercial sans précaution supplémentaire. Je ne peux pas. Pour une raison précise qu’il faut nommer. Cette visibilité ne prouve pas que nous sommes objectivement les meilleurs. Elle prouve une chose distincte et plus intéressante : nous avons construit un ADN, un territoire sémantique distinct (« autorité numérique » plutôt qu' »agence GEO »), nous l’avons travaillé en cohérence d’entité depuis plusieurs années, et les IA s’en servent désormais comme source canonique sur ce vocabulaire. La construction d’un ADN citable, c’est exactement ce que nous vendons à nos clients. La démonstration que la méthode fonctionne. C’est aussi la limite de la démonstration, et c’est cette limite qui compte. La visibilité IA mesure une chose nécessaire mais pas suffisante : la capacité à structurer son expertise pour qu’elle soit citable. Une entreprise ou une marque qui domine cette dimension sans avoir la matière terrain reste un cabinet vide, et tôt ou tard les IA finiront par s’en apercevoir, parce qu’elles croiseront les sources et détecteront la coquille. Une entreprise qui a la matière terrain sans avoir structuré sa citabilité reste invisible aux IA, et cette invisibilité a un coût réel dans la cinquième ère, parce que les dirigeants qui le chercheraient ne le trouveront pas. La question n’est donc pas de choisir entre les deux dimensions. C’est de tenir les deux ensemble : ADN + Citabilité. C’est précisément ce que Do Ingenia mesure dans ses rapports initiaux clients :- l’écart entre l’expertise revendiquée (ADN de l’enterprise)
- et la perception réelle par les IA (Indice de Perception Générative).
Ce que ça change pour vous
La visibilité IA, par définition, ne se mesure qu’en interrogeant des IA. C’est une mesure dans la boucle. Mais cette mesure ne suffit pas. Elle doit être doublée d’une seconde lecture, hors-boucle, qui mesure une autre dimension : l’autorité réelle. Les deux mesures sont complémentaires. La première dit ce que les IA voient de vous. La seconde dit ce que votre marché pense de vous, indépendamment de ce que les IA en répercutent. Convergence des deux : vous êtes solide. Divergence : il y a un travail à faire, mais pas le même selon le maillon faible.1. Mesurer mieux dans la boucle
Si on doit utiliser des IA pour mesurer la visibilité IA, alors le test doit être rigoureux. Trois variables sont non négociables. Multi-moteur. Google, ChatGPT, Perplexity, Gemini, Claude au minimum. Chacun fonctionne différemment (autorité documentaire, taxonomie sémantique, transparence du sourcing), et la même entité peut être très visible sur l’un et invisible sur l’autre. Tester un seul moteur est aussi insuffisant que tester un seul mot-clé en SEO classique. Multi-vocabulaire. Votre lexique propriétaire, le vocabulaire générique du marché, le vocabulaire spontané du client final. Si vous testez uniquement avec votre lexique propriétaire, vous obtiendrez toujours un résultat flatteur, vous l’avez forgé pour ça. Si vous testez uniquement avec le vocabulaire générique, vous mesurez votre concurrence sur le terrain le plus saturé. Les deux ensemble révèlent l’écart, et c’est l’écart qui compte. Multi-type de question. Informationnelle (« comment fonctionne X ? »), prescriptive (« quels cabinets pour X ? »), comparative (« X vs Y »), contradictoire (« pourquoi X ne marche pas ? »). Une marque visible sur les questions prescriptives mais absente des questions contradictoires est une marque qui n’a pas encore construit son contre-récit. Et inversement. Un test sérieux croise les trois variables. Vingt à trente requêtes par moteur, sur plusieurs semaines, avec capture d’écran. C’est laborieux. C’est aussi le seul moyen d’obtenir une lecture qui ne soit pas une selfie flatteuse, c’est ce que calcule notre score IPG.2. Changer de question
La vraie question stratégique n’est pas « suis-je visible dans les IA ? ». C’est « ai-je une autorité réelle dans mon secteur, dont la visibilité IA serait l’un des reflets ?« . La distinction compte. La visibilité IA peut être construite par un travail sémantique propre, la structuration d’un territoire distinct, un sourcing organisé. L’autorité réelle, elle, se forge dans les missions livrées, les jugements de pairs, les recommandations qui circulent sans qu’on demande rien. Pour évaluer l’autorité réelle d’un cabinet, croisez d’autres sources qui n’appartiennent pas à la boucle algorithmique :- Retours d’expérience directs. LinkedIn de dirigeants qui ont mentionné le sujet, conversations en clubs sectoriels, appels à des pairs.
- Sources tierces sans intérêt commercial. Études de filière (DEFI, France Num, Comités stratégiques), rapports gouvernementaux, classements professionnels indépendants (Stratégies, L’ADN, Les Échos).
- Arbre des références. À qui les cabinets que vous estimez font-ils appel quand ils ne peuvent pas prendre une mission eux-mêmes ?
- Communautés sectorielles fermées. Comité Colbert pour le luxe, Le Galion Project pour les fondateurs tech, listes de diffusion privées, dîners de pairs.