
On suit son SEO depuis 25 ans avec la Search Console. On suit ses pubs avec Google Ads, son emailing avec Mailchimp, son funnel avec un dashboard que personne ne lit vraiment. Mais sa visibilité dans ChatGPT, Perplexity, Claude ou Gemini nous sommes aujourd’hui un peu démunie.
C’est véritable un angle mort. Sur les huit articles français récents qui se positionnent en première page Google sur la requête geo seo, aucun ne propose de méthode pour mesurer cette visibilité. Tous expliquent qu’il faut « faire du GEO ». Aucun nous apprend à savoir comment le mesurer et si nos actions sont payantes ou pas du tout.
C’est précisément ce point que cet article entend lever. Tant qu’on ne mesure pas sa part de citation par les IA, on ne pilote pas son autorité numérique. Le terrain a basculé, nous l’avons documenté ailleurs, mais le tableau de bord n’a pas tout à fait évolué. Trois objets sont nécessaires pour passer du discours au pilotage. Un KPI propriétaire que nous avons baptisé IPG (Indice de Perception Générative™). Un protocole de mesure reproductible. Un indicateur comparatif que nous appelons Share of Model.
Pourquoi personne ne mesure (et pourquoi c’est un problème stratégique)
La nappe d’articles francophones consacrés au GEO est saturée. « Qu’est-ce que le GEO », « les sept étapes pour préparer son site », « top dix bonnes pratiques » : la SERP est peuplée de tours d’horizon qui se ressemblent. Cependant, la mesure, elle, n’apparaît nulle part.
Trois raisons possibles à ce silence.
- La première : il n’existe pas encore de KPI partagé pour la visibilité LLM. Sans chiffre commun, chaque acteur produit du contenu en regardant ailleurs.
- La deuxième : les outils SEO classiques, qu’ils s’appellent Search Console, Semrush ou Ahrefs, ne lisent pas les modèles. Ils mesurent ce qui se passe dans les résultats Google, pas ce qui se passe dans les réponses générées.
- La troisième : les LLM eux-mêmes ne fournissent pas de back-office. ChatGPT n’a pas de Search Console. Perplexity ne livre pas la liste des prompts qui ont mentionné votre marque.
Conséquence directe : les dirigeants pilotent en aveugle, ou pire, transposent leurs métriques SEO sur un terrain où elles ne veulent rien dire. Une position en SERP n’a pas d’équivalent dans la réponse d’un moteur de réponse. Une impression Google n’a pas d’équivalent dans une réponse Perplexity.
Et pourtant le canal existe. Un cabinet de pharmacovigilance que nous accompagnons mesure aujourd’hui une centaine de visites entrantes par mois en provenance des moteurs de réponse IA. Sa fondatrice résume :
« On est à une centaine de visites. Bien en dessous de Google. Sauf que la conversion est beaucoup plus immédiate. Le visiteur est beaucoup plus préparé pour contacter, pour trouver l’info. »
Cent visites, ce n’est pas du trafic Google. Mais c’est du trafic mesurable, qualifié, et qui n’apparaîtra dans aucun rapport SEO classique.
L’IPG – Indice de Perception Générative™ : un KPI pour quantifier ce qui n’avait pas de chiffre
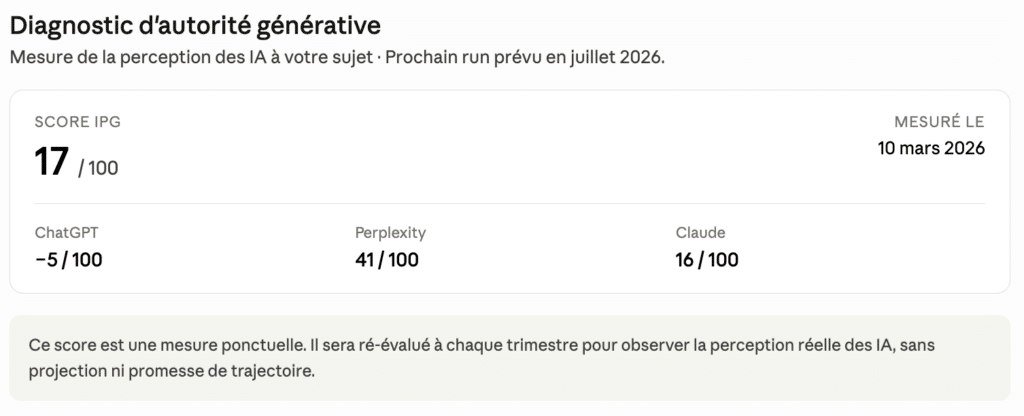
L’IPG – Indice de Perception Générative™ est un indicateur propriétaire que le cabinet a construit pour répondre à une question simple : à quelle fréquence et avec quelle qualité une marque est-elle citée par les IA génératives sur son territoire métier ?
Il agrège deux dimensions.
La fréquence : sur un panel représentatif de prompts, combien de réponses mentionnent la marque.
La qualité : la mention est-elle nominative, en début ou fin de réponse, accompagnée de l’URL, présentée comme source ou comme exemple incident. Une mention nominative en première phrase d’une réponse Perplexity n’a pas le même poids qu’une mention en fin de paragraphe sans lien.
Ce score se distingue volontairement des métriques SEO. Il ne mesure pas un trafic et il ne mesure pas une position. Il mesure une part de voix dans le modèle, c’est-à-dire dans la base d’entraînement et de récupération qui produit les réponses. Le ™ qui l’accompagne ne marque pas la propriété d’une métrique générique : il marque la propriété d’un protocole reconnaissable et reproductible. N’importe qui peut compter des mentions. Peu d’acteurs disposent d’un protocole stabilisé qui produit la même mesure deux trimestres consécutifs.
C’est cette propriété, la reproductibilité, qui transforme un comptage en KPI. Et c’est ce qui rend le pilotage possible.
Le Share of Model : votre part de voix face aux concurrents
Le Share of Voice mesure la part de mentions d’une marque dans la presse. Le Share of Model mesure la part de mentions d’une marque dans les modèles. C’est l’équivalent strict, transposé du paysage médiatique au paysage des LLM.
Le calcul est arithmétique. Sur un panel identique de prompts, on dénombre toutes les marques citées par les modèles testés. On rapporte chaque marque au total : la marque A représente 38 % des citations, la marque B 22 %, la vôtre 4 %. Le Share of Model du segment est posé. C’est factuel : l’écart est mesurable, il peut être piloté.
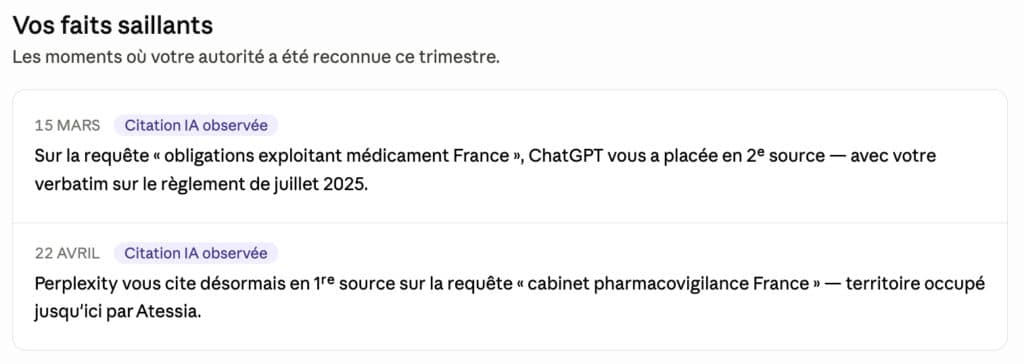
L’intérêt opérationnel est évident. Un Share of Model de 4 % face à un concurrent à 38 % n’est pas un commentaire qualitatif sur la stratégie : c’est un constat. La conversation passe de l’opinion (« on devrait être plus visibles ») à la donnée (« nous représentons 4 % de la voix sur notre territoire »). Et c’est cette donnée qu’une entreprise ou une marque peut suivre dans le temps.
Une nuance de méthode s’impose ici. Le Share of Model varie selon le panel de prompts retenu. Cinquante prompts ne donneront pas la même image que cinq cents. Le protocole doit donc fixer le panel et le faire vivre dans le temps, pas le réinventer à chaque mesure. Sinon on compare des trimestres incomparables, et le pilotage redevient une projection.
Le protocole en 4 étapes (ce qui se passe dans une mesure réelle)
Voici la procédure que nous appliquons pour une mesure trimestrielle.
- Étape 1. Construire le panel de prompts. Cinquante à cent prompts par secteur. Trois familles. Prompts génériques sur le territoire (« quels sont les meilleurs cabinets de X en France »). Prompts comparatifs sectoriels (« comparer A vs B vs C sur Y »). Prompts à intention d’achat (« je cherche un prestataire pour Z, qui recommandes-tu »).
- Étape 2. Interroger les modèles. ChatGPT, Perplexity, Gemini en cœur de panel. D’autres selon le secteur : Mistral pour des contextes francophones réglementés, Claude pour des contextes long contexte. Mêmes prompts, mêmes paramètres, versions consignées.
- Étape 3. Coder les réponses. Présence de la marque oui / non. Position : premier paragraphe, milieu, fin. URL citée ou non. Mention nominative ou évocation indirecte. Codage manuel sur un sous-échantillon, automatisé sur la masse, contrôle croisé.
- Étape 4. Agréger. IPG – Indice de Perception Générative™ : pondération des dimensions précédentes. Share of Model : formule détaillée plus haut. Résultat sur une page : un score, une part, une évolution.
Cadence trimestrielle. Plus fréquent cela ne reflète pas la dynamique réelle des LLM, qui se réentraînent par cycles longs. Moins fréquent fait perdre les signaux de bascule, juste quand un concurrent commence à prendre de la part.
Le piège des « outils GEO » prêts à l’emploi
Plusieurs services SaaS apparus depuis 2025 promettent une mesure de visibilité LLM en un clic. Ils mesurent en réalité un proxy : le plus souvent, la présence de l’URL dans les sources citées par Perplexity. C’est utile, mais ce n’est pas la part de voix réelle dans les réponses livrées aux dirigeants cible.
L’automatisation sans protocole produit du chiffre rassurant, pas du pilotage. C’est un classique de l’instrumentation SaaS : on mesure ce qui est facile à mesurer (les sources Perplexity, la présence d’URL) plutôt que ce qui compte (la part de voix réelle dans les réponses servies aux dirigeants). Le score arrive vite, il rassure le comité de direction, il rentre dans le rapport mensuel. Sa pertinence se vérifie lentement, souvent au moment où un concurrent prend silencieusement 20 points de Share of Model sans qu’on l’ait vu venir.
Ce que la mesure rend possible (et ce qu’elle ne fait pas)
Une mesure utile change la conversation. Elle permet de prioriser les contenus à produire, en pointant les zones où le Share of Model est faible et les sujets où la marque est invisible. Elle permet de détecter en temps quasi réel les concurrents qui prennent de la part. Elle permet de mesurer l’effet d’une publication trois mois plus tard, et donc d’apprendre. Elle permet enfin de justifier l’investissement éditorial auprès d’un comité de direction qui veut autre chose qu’une promesse.
Mais la mesure ne crée pas la matière. Elle ne transforme pas un contenu commodité en source d’autorité. Le score révèle l’écart, le pilotage ne produit pas le contenu.
C’est l’opposition entre la Citadelle Sémantique et la Tour de guet. L’expertise structurée est la citadelle : elle produit la matière qui peut être citée. La mesure est la tour de guet : elle voit ce qui se passe sur les remparts. Sans citadelle, la tour ne voit rien venir parce qu’il n’y a rien à défendre. Sans architecture de connaissance, la mesure n’a pas de matière à observer. Sans tour, la citadelle se fait contourner sans le savoir.
Les deux sont nécessaires. Aucun ne remplace l’autre. C’est ce qui explique pourquoi la mesure seule, vendue par les outils GEO en un clic, ne tient pas dans la durée. Et c’est ce qui explique pourquoi l’expertise seule, sans dispositif de mesure, finit par décrocher d’un terrain qui se redessine sans elle. Construire la citadelle est un travail long : il passe par la digitalisation structurée de l’expertise, l’extraction des verbatims, la mise en cohérence avec le DNA de l’entreprise. C’est le cœur de notre approche du GEO. Bâtir la tour de guet est un travail rapide, mais qui n’a de sens qu’une fois la citadelle posée.
Conclusion
Pourriez-vous, là, maintenant, dire à votre comité de direction quelle est votre Indice de Perception Générative et votre Share of Model sur votre territoire métier ?
Si la réponse est non, ce n’est pas un manque de stratégie. C’est un manque d’instrument. Et un instrument se construit.
Pendant 25 ans, le SEO a appris à se doter de tableaux de bord : Search Console, Analytics, suivi de positionnement, dashboards de toutes sortes. Le GEO traverse aujourd’hui la même bascule, en accéléré. La citadelle d’expertise demande des mois à structurer. La tour de guet, une fois la citadelle posée, se construit en quelques semaines. Mais sans tour de guet, on ne pilote pas une autorité numérique : on espère qu’elle existe, et on s’aperçoit trop tard qu’elle a été contournée.
Diagnostiquer votre visibilité LLM aujourd’hui →
Questions fréquentes
Qu’est-ce que le GEO dans le SEO ?
Le GEO (Generative Engine Optimization) est l’ensemble des pratiques qui visent à rendre une marque visible dans les réponses générées par les moteurs de réponse IA (ChatGPT, Perplexity, Gemini, Claude). Il prolonge le SEO mais sur un terrain différent : on ne vise plus une position dans une liste de liens, on vise une mention dans une réponse rédigée par un modèle.
Que veut dire GEO vs SEO ?
Le SEO optimise pour les moteurs de recherche, qui restituent des listes de liens. Le GEO optimise pour les moteurs de réponse, qui restituent des réponses rédigées. Les deux disciplines partagent une partie des fondamentaux techniques (architecture de site, qualité de contenu, signaux d’autorité) mais divergent sur l’objectif final : être listé n’est plus suffisant, il faut être cité.
Comment savoir si mon entreprise est citée par ChatGPT ?
Il existe trois voies. La voie artisanale : taper soi-même une dizaine de prompts représentatifs de son territoire et noter ce que les modèles répondent. La voie outillée : utiliser un service SaaS qui mesure un proxy (souvent la présence d’URL dans les sources Perplexity). La voie protocolée : construire un panel reproductible, interroger plusieurs modèles, coder les réponses, agréger en KPI. C’est la troisième que nous appliquons sous le nom d’IPG – Indice de Perception Générative™.
Quels indicateurs mesurent la visibilité dans les IA génératives ?
Deux indicateurs sont aujourd’hui exploitables. L’IPG – Indice de Perception Générative™ : un KPI agrégé qui mesure fréquence et qualité de citation par les LLM sur un panel de prompts. Le Share of Model : la part de citations d’une marque rapportée au total des citations sur le panel, c’est-à-dire la part de voix dans les modèles. Le premier est absolu, le second est comparatif.